
Direct Preference Optimization (DPO) explained
A Simpler Way to Fine-Tune Language Models than with RLHF

The go-to method for preference tuning Large language models (LLMs) into conversational agents has been reinforcement learning from human feedback (RLHF). But RLHF, while effective, is complex, costly, and sometimes unstable. Fortunately there is an alternative: Direct Preference Optimization (DPO) does preference tuning from human feedback, but skips reinforcement learning altogether. This method, a runner-up for the NeurIPS 2023 Outstanding Paper Award, offers a streamlined way to incorporate human feedback into LLM training. In this post, we’ll explain how it works.
« Enjoy this post in video format 👇! »
The Problem with Pretrained Language Models
LLMs are pre-trained using self-supervision, where they predict the next word in a sequence based on vast amounts of text data. After training to reproduce ginormous amounts of text data, LLMs are packed with valuable knowledge after pretraining, but they don’t always deliver it when we expect it. For example, if you ask, “When was Einstein born?”, the LLM might correctly respond with “1879”, but it could just as easily reply with another question, like “When was Heisenberg born?”. This response isn’t incorrect; in fact, it’s a valid continuation based on the model’s training data, which likely includes many instances of questions leading to other questions (e.g., exam question sets). However, such outputs can feel unhelpful to users.
To align LLM responses with human expectations and reduce the likelihood of less-preferred outputs, models undergo an additional fine-tuning phase: preference tuning with human feedback.
The first successful way to implement preference tuning with human feedback was RLHF (Reinforcement Learning with Human Feedback).
How RLHF Works
Reinforcement learning from human feedback needs four steps to refine an LLM:
Base LLM: Start with a pretrained language model.
Human Ratings / Preferences: Generate (via humans or via the base LLMs) pairs of outputs for various prompts and have humans rank them based on quality. For example:
Prompt: When was Einstein born?
Output 1: Einstein was born in 1879. | Human preference: 👍(positive)
Output 2: When was Heisenberg born? | Human preference: 👎(negative)
Reward Model: Use the rated outputs as training data for a reward model that predicts human preferences. In other words, the reward model trains to receive any text and annotate it with 👎 or 👍.
Reinforcement Learning: Fine-tune the LLM using the reward model, ensuring it generates outputs that get high scores (
green in formula below) while being regularised to stay close to the output probabilities of the base LLM (blue in formula below). The regularisation makes the model avoid "reward hacking" (e.g., repeating nonsensical phrases that maximize scores given by the reward model).

While effective, RLHF has significant drawbacks:
Complexity and Cost: It requires training an additional reward model. The reward model is initialized with a copy of the LLM, making it computationally expensive.
Instability: Training with reinforcement learning can lead to divergence and other training stability issues.
Enter Direct Preference Optimization (DPO)
DPO eliminates the need for a reward model and reinforcement learning. Instead, it directly optimizes the LLM using a modified cross-entropy loss function. Here’s how it works:
Base LLM: Start with a base / pre-trained LLM (same as with RLHF).
Human Ratings / Preferences: Generate pairs of outputs and have humans label one as "positive 👍" and the other as "negative 👎" (same as with RLHF). For example:
Prompt: When was Einstein born?
Output 1: Einstein was born in 1879. | Human preference: 👍(positive)
Output 2: When was Heisenberg born? | Human preference: 👎(negative)
Contrastive Cross-entropy Training: Fine-tune the LLM to assign higher probability to next tokens from positive outputs 👍 (
green in formula below) and lower probability to next tokens negative ones 👎(red in formula below), ensuring via regularisation the model doesn’t deviate too far from its original generative capabilities (blue in formula below).
This approach skips the reward model entirely, simplifying the process while retaining RLHF’s benefits. The authors of the DPO paper mathematically prove that their loss function finds an optimum equivalent to the optimum of RLHF, offering the same potential outcomes with less complexity.
Why RLHF came before DPO?
There are a couple of reasons RLHF came first:
Historical Context: Early OpenAI researchers likely turned to reinforcement learning because it handles scenarios where loss scores (like human ratings) are non-differentiable. At the time, reinforcement learning seemed like a natural fit, since reinforcement learning is the framework that trains neural networks with nondifferentiable loss functions. In contrast, DPO formulates the learning problem as a contrastive learning setting (increase likelihood of good data samples, decrease the likelihood of bad data samples) instead of letting the LLM generate any kind of output during preference tuning and apply the reward model to it.
Data Assumptions: RLHF allows for the reward model to annotate large datasets after being trained on a small human-labeled dataset. While this was an attractive idea initially, in practice, human feedback datasets have grown significantly to cover as many edge cases and capabilities, making this advantage less critical.
Does DPO Perform as Well as RLHF?
The DPO paper presents impressive results. The authors trained GPT-J (6 billion parameters) using DPO and RLHF on tasks like IMDb sentiment generation and TL;DR summarization. They evaluated the outputs with GPT-4, which has become a common proxy for human evaluation. The results? DPO outperformed RLHF.
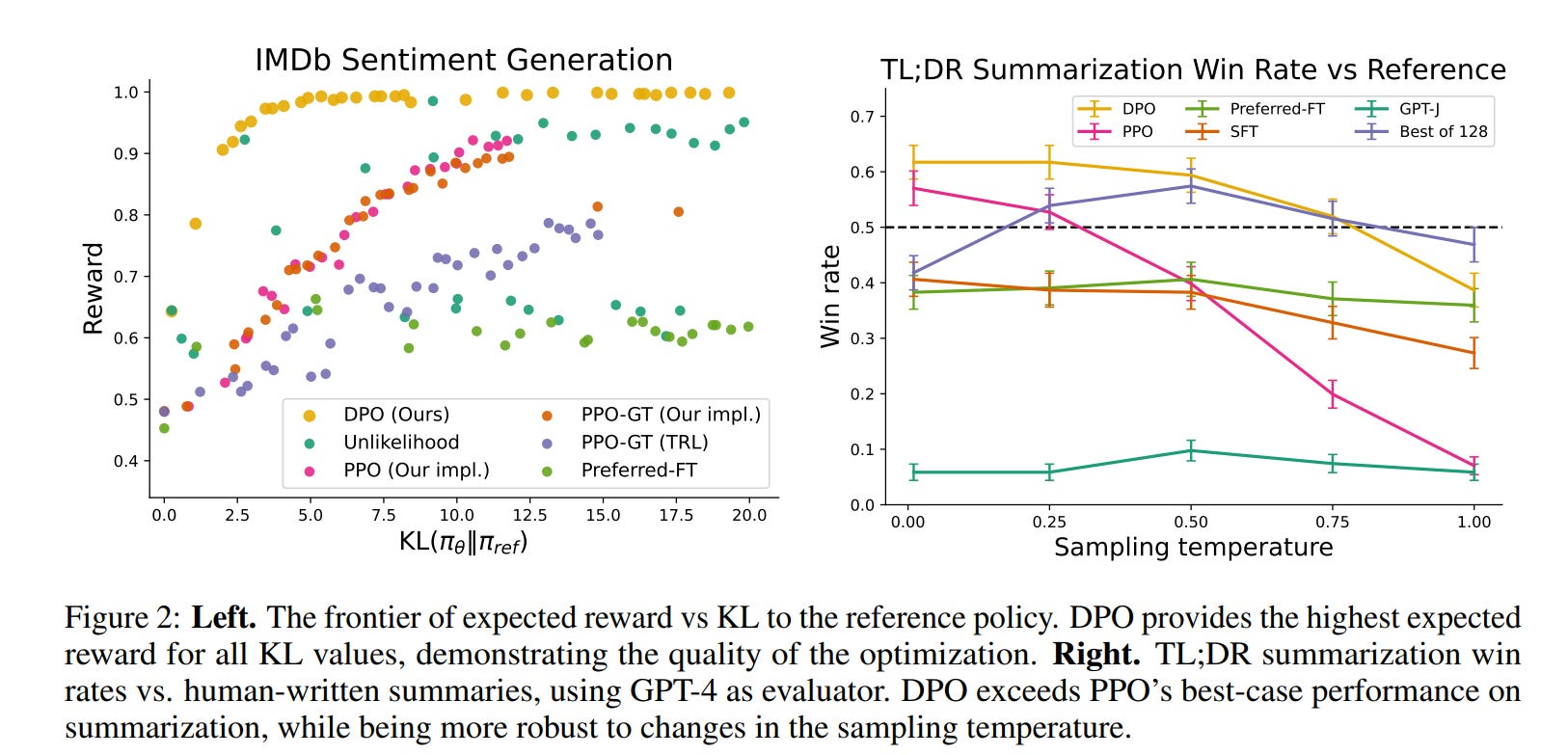
The authors also tested DPO on the Anthropic HH dataset with a Pythia model (2.8 billion parameters) and showed strong performance. However, the authors didn’t test larger models, likely due to resource constraints in a university setting. Encouragingly, their open-sourced code has already been applied to newer models like LLaMA-2 and Zephyr, with promising results.

Limitations and Future Directions
While DPO streamlines the fine-tuning process, it relies on binary labels—human-annotated positive and negative pairs—for training. In contrast, RLHF offers greater flexibility by enabling the reward model to work with more granular annotations, such as ratings on a scale from 1 to 5.
Additionally, RLHF allows the reward model to scale and annotate larger datasets with diverse completions for the same prompts, providing broader training opportunities than DPO. However, as human-labeled datasets continue to expand to address diverse needs like coding, mathematics, and bias avoidance, the comparative advantage of RLHF in this regard becomes less significant.
Thus RLHF, despite its effectiveness, remains cumbersome and resource-intensive. DPO offers a faster, more stable alternative by removing the need for a reward model and reinforcement learning. This innovation makes fine-tuning accessible to a broader range of practitioners and researchers.
If you’re working on fine-tuning LLMs, DPO might be worth exploring. Do you see yourself using DPO in your projects? Let us know in the comments!
Thanks for reading! If you enjoyed this breakdown, subscribe to stay updated on the latest AI advancements. See you in the next post!
Hey! Thanks for the great post about DPO vs RLHF. Just a couple of things:
1. DPO was runner up for last year's NeurIPS (2023).
2. I'm not sure whether this is just my browser or substack issue, but the MathJax isn't rendering on the web browser version of Substack.
\( \mathcal{L}_{\text{DPO}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\textcolor{green}{\pi_\theta(y_w \mid x)}}{\textcolor{blue}{\pi_{\text{ref}}(y_w \mid x)}} - \beta \log \frac{\textcolor{red}{\pi_\theta(y_l \mid x)}}{\textcolor{blue}{\pi_{\text{ref}}(y_l \mid x)}} \right) \right]. \)