
How OpenAI made o1 "think"
Here is what we think and already know about o1 reinforcement learning.

Here is what we think about the training procedure of OpenAI #o1. We speculate based on all the breadcrumbs we could find, how exactly reinforcement learning (RL) helped train the model to “think” by producing private Chain-of-Thought tokens before answering.
« Enjoy this post in video format 👇! »
OpenAI's New Model: o1 – What Makes it Special?
OpenAI’s latest model, o1, has quickly made waves with its capabilities, as it can finally handle tasks like counting the number of ‘r’s in “strawberry”! This ability even inspired the model’s development codename: “Strawberry” 🍓.

But, as with all things AI, there are still some quirks—sometimes it doesn’t count the ‘r’s correctly, and oddly enough, it has issues counting ‘t’s too!


Still, let’s cut the o1 model some slack. Despite some some LLM-specific hiccups, it’s a significant improvement over GPT-4o. The model has a remarkable ability to "think" before answering, and it’s much better at coding and solving complex math problems. By “complex”, we mean the kind of math problems that most of us struggle with if we haven’t practiced for years.
So, what’s going on under the hood with OpenAI o1? While OpenAI hasn’t disclosed every detail about the model, we've pieced together some well-informed speculations from available insights. Let's dive in!
What Does “Thinking” Mean for OpenAI o1?
First, a quick wording clarification: When we say o1 can “think” before answering, we’re referring to its ability to produce Chain-of-Thought (CoT) tokens—helper tokens generated before the model delivers its final answer. These CoT tokens help the model break down complex problems step by step, resulting in a more accurate response.
Unfortunately, we don’t get to see the raw CoT tokens in the ChatGPT interface. Instead, we’re shown a summary generated by the model. While it would be fascinating to inspect the full chain of reasoning, OpenAI has chosen to hide it, to maintain a competitive advantage.
How Does OpenAI o1 Work?
Now, let’s speculate on how OpenAI o1 works. OpenAI has kept the specifics under wraps, but we’ve been given a few breadcrumbs to follow. In their technical post, OpenAI mentions using reinforcement learning (RL) to train the model to produce the Chain-of-Thought (CoT) tokens.

The model, unlike previous ones such as GPT-4o, goes through two phases of using compute resources:
Train-time compute: OpenAI invests significant computational resources to teach the model with RL to “think” by generating CoT tokens.
Test-time compute: During inference, the model takes extra time to produce the necessary tokens to arrive at the best possible answer.
In the technical post, OpenAI shares graphs showing how training and test-time compute scale with the model’s performance shown above. Now, let's look into how the model might have been trained.
Training the o1 Model with Reinforcement Learning
A possible way to understand how o1’s training works is by referencing a paper OpenAI published last year: 📃 Let's verify paper: Lightman, Hunter, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. "Let's verify step by step."(2023) https://arxiv.org/abs/2305.20050
In it, they trained reward models to detect hallucinations using two types of supervision:
Outcome supervision: Provides feedback based on the final result.
Process supervision: Gives feedback on each step within the model’s Chain-of-Thought (CoT).
Let’s break that down a bit further.
Outcome Supervision: Providing Feedback for the Answer
Outcome supervision rewards the model based on whether the final answer is correct. In tasks like math or coding, this is easy to automate—since answers are either correct or not, there’s no need for human labellers. With enough data, OpenAI can train a reward model that guides the LLM in learning to arrive at correct answers.

This method seems especially well-suited for coding and math tasks, where training data can be generated synthetically and checked with compilers or verifiers. And, as expected, these are precisely the areas where o1 shines. 👇

Process Supervision: Improving Each Step
The second crucial ingredient in o1’s training is process supervision, where the reward model evaluates each step in the Chain-of-Thought. But how is this accomplished?

By employing human labellers to annotate the correctness of each step in the solutions generated by the model.

This process is labor-intensive and costly, but even a good enough amount of annotated data allows OpenAI to train a reward model that provides feedback during training, as exemplified in the figure: 👇

While the the paper I referenced focuses on training reward models and does not further discuss LLM training with those reward models, it’s a reasonable assumption that a similar approach was used to train o1. Essentially, OpenAI could initialize these reward models from a GPT-4 base, which would already contain vast amounts of pre-trained knowledge, making them ideal for the task.
During the training of o1, the model could thus generate possible Chain-of-Thought paths, similar to how AlphaGo generates possible moves in a game of Go. The model’s task is to extend the prompt by producing the most promising CoT path according to the process supervision reward model, and to ultimately generate a good answer according to the outcome supervision reward model.
By running reinforcement learning on massive datasets with answers, the CoT generator in o1 could get better and better at choosing the right paths. Over time, the model improves its reasoning process, going beyond simple memorization of answers.
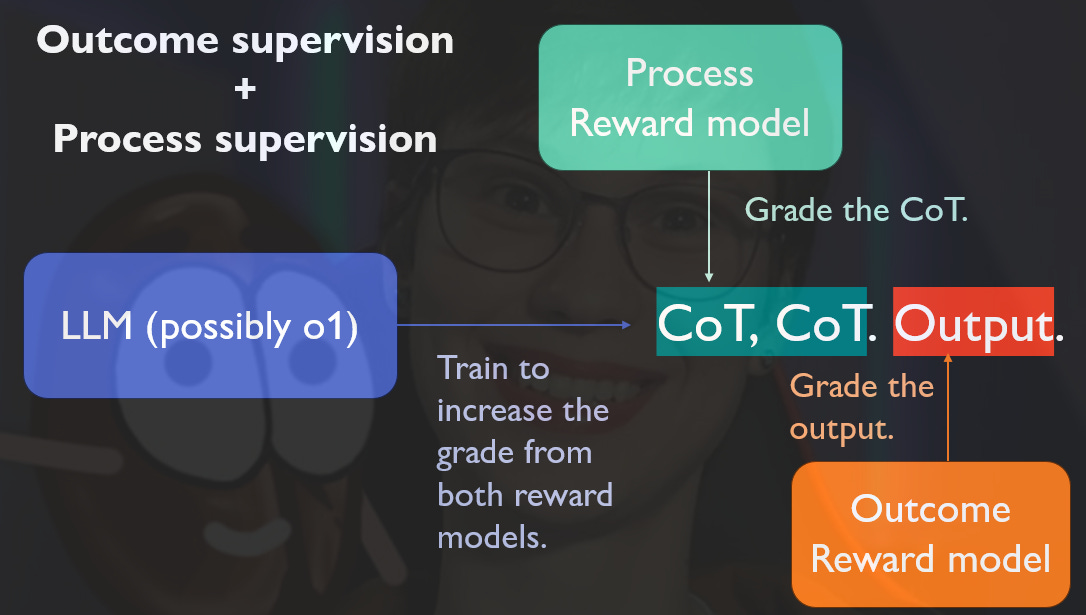
It's certainly possible to train o1 using just one of the reward models. In fact, training without a process supervision reward model could also be a way in which OpenAI could train o1 without human-labeled data. By simply rewarding Chain-of-Thought (CoT) paths that lead to the correct answer and penalizing those that don’t, o1 can be trained in a more automated and self-generated data-driven manner.
Inference-Time Chain-of-Thought
When you ask o1 a question, it could generate one or more Chain-of-Thought rollouts to arrive at the best answer, similar to how AlphaGo plays out possible moves before choosing the best one. However, we don’t know whether the model uses one or multiple CoT rollouts, because OpenAI hides all the intermediate steps. You only see the final answer, which is essentially a summary of the “reasoning” process.
😜Since the Chain-of-Thought tokens are hidden from the user, you're essentially paying for the additional compute time that produces them, even though you don’t get to see the full reasoning behind the answer. Noice!
How Good is the o1 Model?
So, how does o1 stack up against GPT-4o? While it doesn’t always outperform GPT-4o in tasks that require less reasoning, like style transfer or simpler content, o1 truly excels in coding, data analysis, and complex math. These are areas where synthetic data for training is readily available, and verification is relatively easy, which explains why o1 performs so well in these tasks.

This makes o1 a great tool for scientists, developers, and anyone dealing with complex data processing tasks. While previous LLMs often struggled with these areas, o1 fills that gap remarkably well, up to a point. Star mathematician Terence Tao wrote that OpenAI o1 is “mediocre, but not completely incompetent, gradate student”. In contrast, GPT-4o was “closer to an actually incompetent graduate student”.

Wrapping Up
At the end of the day, OpenAI o1 is still an LLM, and as such, it’s not without its faults. You’ll still see some funny failures and hallucinations here and there. These are specific to LLMs, which o1 still is. Despite being trained with reinforcement learning to generate useful CoT tokens, o1 is still an LLM producing the most next likely token; the correctness and usefulness of this next token was rated by reward models. Only that the reward models that evaluate o1’s outputs are also LLM-based, meaning they, too, are susceptible to mistakes.
But with improvements in coding, math, and reasoning tasks, o1 could become an indispensable tool in scientific and technical fields. As always, make sure to apply a healthy dose of expertise when using any LLM and stay curious about how these technologies evolve.
Thanks for reading! If you enjoyed this post and want to dive deeper into AI topics, don’t forget to subscribe to stay updated on the latest innovations. See you next time!