
LoRA Explained (Low-Rank Adaptation)
A Game-Changer for Fine-Tuning Large Language Models (LLMs)

Large language models like GPT-3, LLaMA 2, and Falcon are remarkable for their general-purpose capabilities. However, when you need them to specialize—for instance, to create a banking chatbot or an assistant with deep medical expertise—prompt engineering and few-shot examples often aren’t enough. Fine-tuning becomes essential, but fine-tuning these massive models presents its own set of challenges.
This is where LoRA (Low-Rank Adaptation) comes in, offering a more efficient and cost-effective way to fine-tune large models. In this post, we’ll explore how LoRA works, why it’s powerful, and how it compares to other approaches.
« Enjoy this post in video format 👇! »
The Challenge of Fine-Tuning Large Models
Fine-tuning large models is no small feat. These models contain tens to hundreds of billions of parameters, and during fine-tuning, we need enough GPU memory to store:
The model’s parameters and activations (just like during inference).
Additional space for gradients and optimizer states required during backpropagation.

This second requirement effectively doubles the memory requirements during training compared to inference, which is prohibitive for most small setups when tuning large models.
What Is LoRA in a nutshell?
LoRA, introduced by Microsoft, sidesteps this problem by freezing the original model weights and introducing a small set of additional parameters. These new parameters are trained (adapted) during LoRA finetuning to capture the differences we need to add to the frozen model to adapt it for a specific task.
After finetuning, during inference, these additional weights are merged with the original model weights, so the GPU memory requirement remains the same as before fine-tuning. This, and the fact that we do not train as many parameters as the original models has, makes LoRA incredibly efficient.
How LoRA Works
LoRA’s key insight is that we don’t need to fine-tune all the parameters in the model. Instead, it uses low-rank decomposition to focus on the most important changes. Here’s a breakdown:
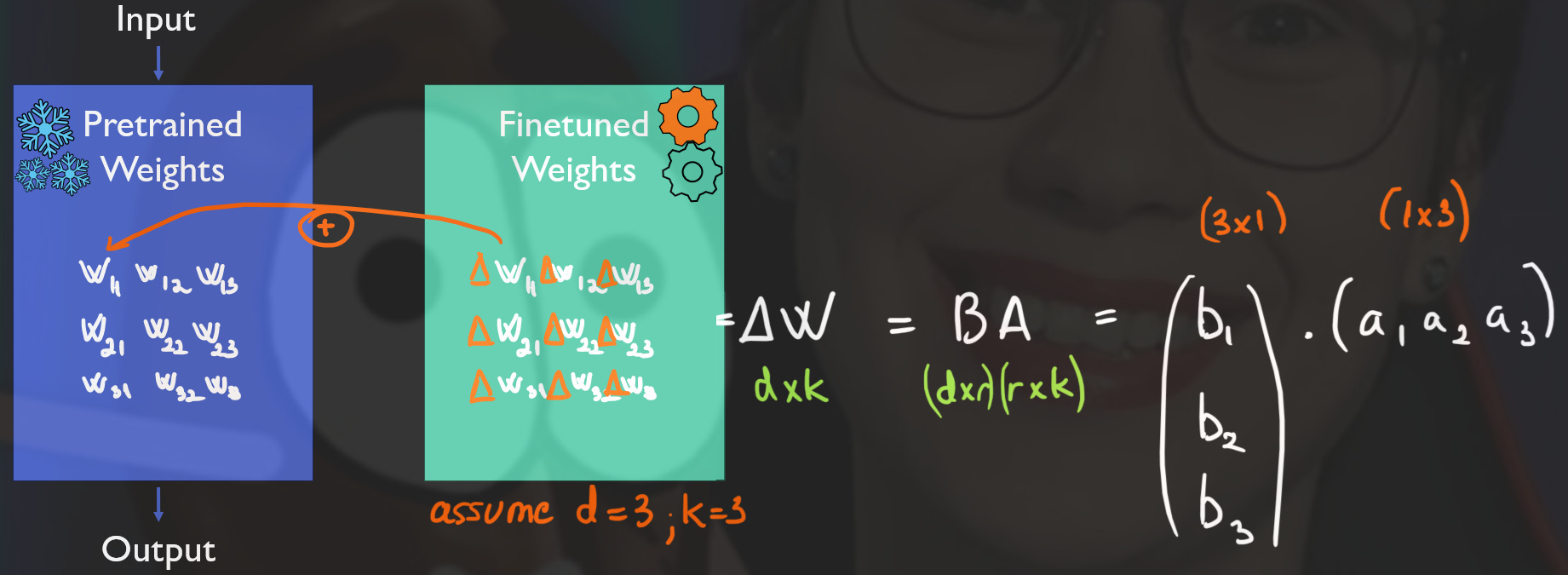
Freezing Weights: LoRA leaves the original model weights W untouched.
Adding Parameters: Instead of directly fine-tuning the weight matrix W, LoRA represents the changes ΔW as the product of two smaller matrices A and B, such ΔW = AB.
A reduces the matrix’s W dimensionality to a dimension r, called rank (see figure below).
B restores the original dimensionality of W.
Efficiency: The product of A and B captures the necessary weight adjustments for fine-tuning, while requiring fewer parameters to train. For example, instead of tuning a matrix with 9 parameters of ΔW, we might only need to tune 6 (A has 3 parameters in the figure example below, while B has also 3, thus 6 in total).
By selecting a suitable rank r (hyperparameter), LoRA balances efficiency and performance. A rank that’s too low loses critical information, while a rank that’s too high wastes computational resources.
LoRA vs. Other Fine-Tuning Approaches
LoRA isn’t the only method for fine-tuning large models, but it has distinct advantages over popular alternatives:
Adapter Layers
How They Work: Adapter layers add a small, trainable layer to each Transformer block. During fine-tuning, only these layers are updated.
Pros: Extremely parameter-efficient, sometimes requiring as little as adding 1% of the model's total parameters to train.
Cons: Adapter layers introduce latency during inference because they must be processed sequentially, which can slow down large-scale deployments.
Prefix Tuning
How It Works: Prefix tuning adjusts a set of randomly initialized input vectors (called prefixes) to steer the model toward task-specific behaviour.
Pros: Avoids modifying the main model and provides a continuous form of prompt engineering.
Cons: Reduces the effective input size by occupying part of the sequence length and is tricky to optimize.
While both methods remain popular, LoRA (and its variants such as Galore) has gained significant traction due to its balance of efficiency and simplicity.
Why LoRA Stands Out
Cost Efficiency: By reducing the number of trainable parameters, LoRA lowers both computational and storage requirements during fine-tuning.
Versatility: It works seamlessly with various tasks and domains, from creating domain-specific chatbots to adapting models for unique datasets.
Scalability: Unlike methods that add latency or require complex tuning, LoRA integrates smoothly into existing workflows.
LoRA has revolutionized fine-tuning for large language models, making it more accessible and efficient for researchers and practitioners. Whether you’re working with open-source models like LLaMA or experimenting with GPT-3, LoRA empowers you to specialize these models without running out of VRAM.
If this explanation clarified LoRA for you, don’t forget to share this post! For more insights into AI and machine learning, subscribe to my blog. Until next time—happy fine-tuning!