
MAMBA and SSMs Explained
State Space Models (SSMs) and Selective SSMs: MAMBA explained

In the ever-evolving world of AI, there's a new contender making waves—MAMBA. It's been generating quite a buzz, and for good reason. Some even say it could replace the ubiquitous Transformer. Surprisingly, the MAMBA paper was initially rejected at ICLR, but this hasn't stopped it from gaining traction in the AI community.
In this post, we'll dive deep into what makes MAMBA so exciting and why it's being hailed as a game-changer. To fully understand MAMBA, we first need to explore the concept of State Space Models (SSMs), which form the foundation of this new architecture. So, grab a cup of coffee and let's break it down.
« Optional: Enjoy this post in video format 👇! »
A Case for SSMs
MAMBA, a groundbreaking architecture introduced by Albert Gu and Tri Dao (the latter name you might recognize from his work on Flash Attention 1, 2, and 3—has quickly captured the attention of the AI community. Its main innovation is the enhancement of State Space Models (SSMs), which were already faster and more memory-efficient than Transformers, especially for long sequences.
However, SSMs had a significant drawback—they weren't as accurate as Transformers. MAMBA addresses this by introducing Selective State Space Models, or Selective SSMs, which retain the speed and efficiency of traditional SSMs while significantly improving accuracy, making them competitive with Transformers.

Before diving into Selective SSMs, let’s first understand SSMs.
What Are State Space Models (SSMs)?
State Space Models are not new to the AI world, but they haven't been as popular as Transformers—until now. SSMs are often part of larger neural network architectures and work similarly to linear Recurrent Neural Networks (RNNs). In essence, like RNNs, SSMs process input tokens one after the other, where the hidden representation of the previous token (h_{t-1}) and the current input token (x_t) are combined to produce the next hidden representation (h_t).

In more detail, SSMs are also known as S4 models and use four sets of matrices—Delta, A, B, and C—to process inputs. Each of these matrices plays a crucial role: (LaTeX might not render correctly in the email: open the blog post to see LaTeX formulas)
Delta modifies the weights in the A and B matrices.
A determines how much of the hidden state should propagate from token to token.
B controls how much of the input enters the hidden state.
C transforms the hidden state into the output.
These components work together in a two-step process. First, Delta modifies matrices A and B during what's called the "discretization step", converting them into A-bar and B-bar. This step is necessary to transition from continuous to discrete settings, allowing the model to handle discrete data effectively.
Next, in the linear RNN step, the modified matrices are used to process each token sequentially. The hidden state from the previous token is transformed using A-bar, and B-bar is applied to the current input. These two components are then combined to produce the hidden state for the current token, which can be further processed to make predictions (e.g., next token prediction), classify sequences (whether it is ape DNA or not ape DNA), or perform other tasks. For example, like in transformers, we can use this last representation to classify for example, which of the 50 thousand words in the vocabulary is likely to come next.
The Importance of the Discretization Step
The discretization step is critical because SSMs are derived from continuous differential equations. These equations describe how variables change over time in infinitesimally small steps.
In a continuous setting, we would move in infinitesimally small steps along the curve, allowing for a smooth transition from one state to the next. However, in a discrete setting, we take these steps in a more segmented manner, moving from one state to another in distinct intervals.
So, for discrete computation, the differential equation needs to be converted the SSM equation where we take discrete steps to update h, according to a step size defined by Delta:

The step size Delta (Δ) determines the granularity of the discretization process, essentially controlling how finely we break down the continuous curve into discrete steps (producing us A-bar and B-bar). Choosing a larger Delta allows for bigger jumps between states, which can speed up calculations but at the risk of overshooting the curve and introducing errors in the approximation. On the other hand, a smaller Delta results in finer, more accurate steps but requires more computational effort.
Delta is a hyperparameter that can be adjusted based on the specific requirements of the model. For instance, it might be set as a scalar value relative to the sequence length. However, since the hidden state h_t typically has many dimensions (due to the high-dimensional nature of input embeddings), Delta can also be represented as a matrix, with each entry corresponding to a different dimension and thus allowing for variable step sizes across those dimensions.
To correctly apply this discretization step (according to mathematical derivations— similar, simple derivation here), it's necessary to convert the matrices A and B from their continuous forms into their discrete counterparts, A-bar and B-bar, using the specific formulae below.
However, in practice these equations were simplified by the authors (applying a similar equation for B-bar as for A-bar) and I see nor reason why one could not learn A-bar and B-bar directly from data (take my opinion with a grain of salt🧂).
In a nutshell: SSMs are “just” the discretized version of this continuous differential equation!
Why SSMs Are Fast
Transformers are known for their efficacy, but they have a significant drawback: the self-attention mechanism scales quadratically with the sequence length. This means that as the sequence length doubles, the computation time and memory required increase fourfold. SSMs, on the other hand, scale linearly. Doubling the sequence length only doubles the computation time and memory, making them much more efficient for long sequences.
Convolution Trick – How Parallelization Works in SSMs During Training
Although SSMs process tokens sequentially like RNNs, they are faster and parallelizable during training. This is because SSMs, like linear RNNs, involve linear computations, allowing them to precompute and execute matrix multiplications in parallel for all tokens during training. However, at inference time, SSMs must process tokens one after the other, which is where they slow down compared to their training.
Now more detail about the magic that lies in the linear nature of the computations within SSMs: Throughout the sequence, SSMs use the same matrices—A-bar, B-bar and C—to process input tokens. This consistency allows us to precompute many of the operations in advance.
Let’s apply the SSM equations a few steps to see where this goes:
When processing a sequence, the hidden representation for the first token is typically initialized, often assumed to be zero. For this first token, the hidden state is computed using the matrix A-bar applied to the previous hidden state (which is zero) and the matrix B-bar applied to the input token. This gives us the output for the first token.
For the second token, the process repeats, but this time using the hidden state generated from the first token. The key observation here is that the pattern of matrix multiplications—A-bar, B-bar and C—remains consistent across tokens, forming a pattern:
We do not need to know what input x will come next in the batch, because we can precompute all needed matrix multiplications ahead of time. Instead of recalculating the same operations for each token, we perform the necessary multiplications once and store the results. These precomputed results can be combined into a large matrix, K, which encapsulates all the required operations.
Once we have matrix K, we can efficiently multiply it by the matrix of input vectors in a single step, using a convolution operation. Convolutions are particularly fast on GPUs, making this approach highly efficient. This means that instead of processing each token one by one, we can compute the outputs for all tokens simultaneously, significantly speeding up the training process.
In summary, the ability to precompute and store repetitive operations, combined with the power of GPU-accelerated convolutions, allows SSMs to achieve parallelization during training, despite their sequential nature. This is one of the reasons why SSMs can be both fast and efficient, making them competitive with other architectures like Transformers.
Selective State Space Models (Selective SSMs)
MAMBA takes SSMs to the next level by introducing Selective State Space Models. Traditional SSMs apply the same matrices—Delta, A, B, and C—to all input tokens, making them somewhat inflexible. This uniform approach doesn't allow the model to prioritize certain tokens over others, which can limit its effectiveness in processing complex sequences where some inputs are more critical than others.
Selective SSMs address this by allowing these matrices to vary depending on the input token, enabling the model to focus on more important tokens and ignore less relevant ones. Instead of using the same matrices for every token, Selective SSMs compute different Delta, B, and C matrices for each input token. This is achieved through linear layers that take the embedding of each token as input and generate corresponding matrices.
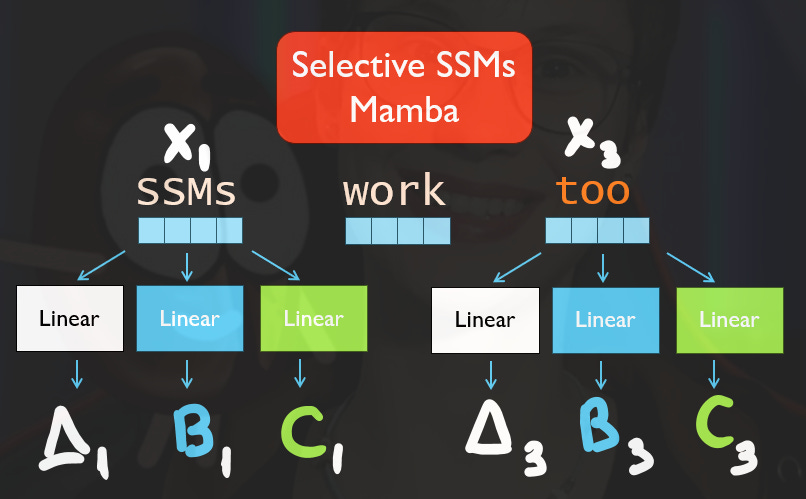
For instance, a Delta-specific linear layer processes the current token's embedding to compute a unique Delta matrix. Similarly, B-specific and C-specific linear layers generate unique B and C matrices based on the token's embedding. This customization allows the model to adapt its processing strategy for each token, effectively learning to focus on more important tokens while de-emphasizing less relevant ones—a role similar to the attention mechanism in Transformers.

This flexibility, however, comes with a trade-off: the convolution trick used to speed up traditional SSMs during training becomes impossible. To overcome this, MAMBA employs a parallel associative scan, an advanced algorithmic technique that allows the model to maintain its speed and efficiency even with the added complexity of Selective SSMs.
Parallel Associative Scan
This concept is rooted in the idea that we can store intermediate steps to perform operations more efficiently.
Take the example of computing sums in an array. Suppose you have an array with elements like [ 3, 1, 7, 0, 4 ], and you want to compute the sum of these elements. A straightforward approach would involve sequentially adding each element to the sum of all previous elements. However, a more efficient method is to compute the all-prefix-sums first.
Here’s how it works:
Start by adding the first element (3) to its predecessor (which is zero).
Then add the result (3) to the next element (1) to get 4.
Next, add this sum (4) to the following element (7) to get 11, and so on.
This would return [ 0 3 4 11 11 15 16 22 ].
By doing this, you’ve precomputed sums for different segments of the array. Now, if you want to find the sum of just the last 4 elements of [ 3, 1, 7, 0, 4 ], you can simply subtract the appropriate prefix sum from the total, instead of recomputing the entire sum. For example, to find the sum of the last three elements (1, 7, 0, 4), you can subtract from [ 0 3 4 11 11 15 16 22 ] 22 minus 3.
This concept, known as a scan or prefix sum, is crucial for optimizing sequential processes. However, implementing these efficient algorithms on GPUs requires careful consideration of hardware-specific details. For instance, in a framework like PyTorch, a naïve implementation of this scan might be slower due to how data is handled in memory.

To overcome this, the authors of the MAMBA model implement a sophisticated approach:
Delta, A, B, C matrices are read from the slower HBM (High Bandwidth Memory) on the GPU to the faster SRAM (Static RAM).
The discretization of matrices A and B is performed in this fast SRAM.
Parallel associative scanning, a method that allows for rapid computation by storing intermediate results, is also conducted in SRAM.
Finally, the results are multiplied with matrix C and written back to the slower HBM.
This intricate process ensures that the computations are not just theoretically fast but also optimized for the specific architecture of GPUs, making the MAMBA model highly efficient.
For those interested in diving deeper into the implementation details, here are two excellent resources:
For a pure PyTorch implementation, check out this awesome repository by Rudy Pei.
For a comprehensive CUDA tutorial on associative scans, NVIDIA provides an in-depth guide in GPU Gems.
The MAMBA Architecture
The MAMBA architecture builds on the concept of Selective SSMs, stacking multiple layers to create a powerful and flexible model. Each MAMBA layer includes a Selective State Space module, as well as additional components designed to enhance the model's performance:

Dimensionality Increase: A linear layer first doubles the dimensionality of the input token embedding, giving the network more space to process information.
1D Convolution: This layer processes the output from the previous sublayer, using the Swish (SiLU) activation function to enhance information flow.
Selective State Space Module: This module processes the output from the convolution, applying the Selective SSM logic.
Gated Multiplication: The output of the Selective SSM is multiplied by the result of another linear layer processed through a Swish activation, which acts as a measure of similarity between the SSM output and the current token embedding.
Dimensionality Reduction: Finally, a linear layer reduces the dimensionality back to the original size, completing the processing for this layer.
Multiple MAMBA layers are then stacked on top of each other, similar to how Transformer layers are stacked, creating a robust architecture capable of handling various tasks.
If you think that this architecture is complicated, then think about how the transformer layer layer also has a lot of components: self-attention, a feed-forward network, normalization, residual layers…, and so on!
MAMBA's Performance and Impact
MAMBA's innovations have paid off. It performs on par with Transformers, as evidenced by its scaling laws in language modeling tasks. Not only does it match Transformers in terms of perplexity on large datasets like The Pile, but it also outperforms them as sequence lengths increase.
MAMBA is also extremely fast. At a batch size of 128, MAMBA with 1.4 billion parameters can process 1,814 tokens per second, far outperforming the Transformer, which encounters an Out of Memory (OOM) error. Even at a smaller batch size of 8, MAMBA processes 744 tokens per second, significantly outpacing the Transformer, which manages only 265 tokens per second.

This efficiency makes MAMBA particularly well-suited for tasks involving very long sequences, such as DNA sequence classification or autoregressive audio modeling, where it has set new state-of-the-art results.
Building on MAMBA
The excitement around MAMBA has led to rapid adoption and experimentation within the AI community. Despite its initial rejection at ICLR, MAMBA has already inspired several new models and applications. Just to name a few:
Mixture of Experts Mamba for even larger scale models.
Vision Mamba for image processing.
MambaByte, which learns directly from raw bytes without relying on tokenizers, making it ideal for extremely long sequences.
MAMBA 2 came out in the meantime, check it out.
These developments suggest that MAMBA could be the architecture that brings RNNs, in the form of SSMs, back into the spotlight, potentially challenging the dominance of Transformers in the process.
Thoughts
MAMBA offers a fast, efficient, and powerful alternative to Transformers. While only time will tell whether MAMBA and Selective SSMs will replace Transformers, the early results are promising. With ongoing research and development (for example by combining SSMs with Transformers, e.g. in Jamba), MAMBA could very well be the architecture that defines the next generation of AI models.
Thank you for reading! If you enjoyed this post, don't forget to subscribe to the blog or the YouTube Channel and stay tuned for more deep dives into the latest AI innovations.
One of the best blogs read ... lovely